本文共 4584 字,大约阅读时间需要 15 分钟。
与django等网络框架一样flask同样是非常友好,值得关注的网络框架
一个最小的应用
一个最小的 Flask 应用如下:
from flask import Flaskapp = Flask(__name__)@app.route('/')def hello_world(): return 'Hello World!'if __name__ == '__main__': app.run() 把它保存为 hello.py 或其他类似名称并用你的 Python 解释器运行这个文件。请不要 使用 flask.py 作为应用名称,这会与 Flask 本身发生冲突。
$ python hello.py * Running on http://127.0.0.1:5000/ 现在,在浏览器中打开 ,就 可以看到问候页面了。
那么,这些代码是什么意思呢?
- 首先我们导入了 类。这个类的实例将会成为我们的 WSGI 应用。
- 接着我们创建了这个类的实例。第一个参数是应用模块或者包的名称。如果你使用一个 单一模块(就像本例),那么应当使用 __name__ ,因为名称会根据这个模块是按 应用方式使用还是作为一个模块导入而发生变化(可能是
'__main__',也可能是 实际导入的名称)。这个参数是必需的,这样 Flask 就可以知道在哪里找到模板和 静态文件等东西。更多内容详见 文档。 - 然后我们使用 装饰器来告诉 Flask 触发函数的 URL 。
- 函数名称可用于生成相关联的 URL ,并返回需要在用户浏览器中显示的信息。
- 最后,使用 函数来运行本地服务器和我们的应用。
if __name__ =='__main__':确保服务器只会在使用 Python 解释器运行代码的 情况下运行,而不会在作为模块导入时运行。
按 control-C 可以停止服务器。
外部可见的服务器。
运行服务器后,会发现只有你自己的电脑可以使用服务,而网络中的其他电脑却不行。 缺省设置就是这样的,因为在调试模式下该应用的用户可以执行你电脑中的任意 Python 代码。
如果你关闭了 调试 或信任你网络中的用户,那么可以让服务器被公开访问。只要像 这样改变 方法的调用:
app.run(host='0.0.0.0') 这行代码告诉你的操作系统监听一个公开的 IP 。
调试模式
虽然 方法可以方便地启动一个本地开发服务器,但是每次 修改应用之后都需要手动重启服务器。这样不是很方便, Flask 可以做得更好。如果你 打开调试模式,那么服务器会在修改应用之后自动重启,并且当应用出错时还会提供一个 有用的调试器。
打开调试模式有两种方法,一种是在应用对象上设置标志:
app.debug = Trueapp.run() 另一种是作为参数传递给 run 方法:
app.run(debug=True) 两种方法的效果相同。
注意
虽然交互调试器不能在分布环境下工作(这使得它基本不可能用于生产环境),但是 它允许执行任意代码,这样会成为一个重大安全隐患。因此, 绝对不能在生产环境 中使用调试器 。
运行的调试器的截图:
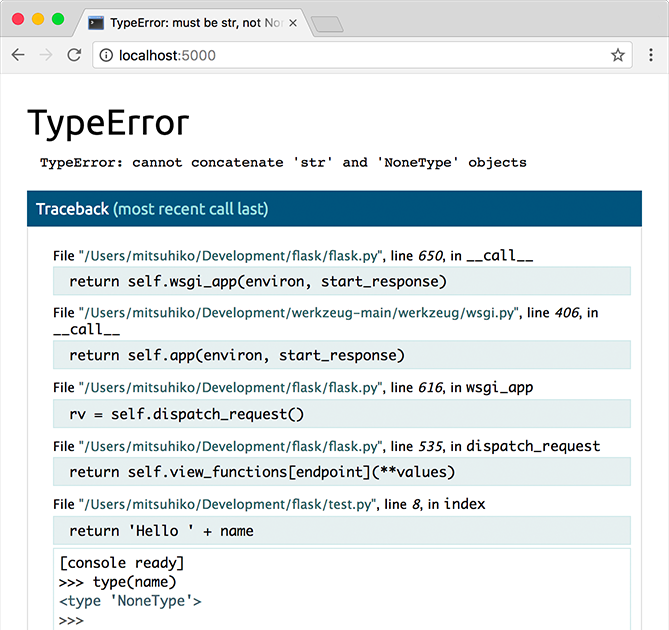
想使用其他调试器?请参阅 。
路由
现代 web 应用都使用漂亮的 URL ,有助于人们记忆,对于使用网速较慢的移动设备尤其 有利。如果用户可以不通过点击首页而直达所需要的页面,那么这个网页会更得到用户的 青睐,提高回头率。
如前文所述, 装饰器用于把一个函数绑定到一个 URL 。 下面是一些基本的例子:
@app.route('/')def index(): return 'Index Page'@app.route('/hello')def hello(): return 'Hello World' 但是能做的不仅仅是这些!你可以动态变化 URL 的某些部分,还可以为一个函数指定多个 规则。
变量规则
通过把 URL 的一部分标记为 <variable_name> 就可以在 URL 中添加变量。标记的 部分会作为关键字参数传递给函数。通过使用 <converter:variable_name> ,可以 选择性的加上一个转换器,为变量指定规则。请看下面的例子:
@app.route('/user/ ')def show_user_profile(username): # show the user profile for that user return 'User %s' % username@app.route('/post/ ')def show_post(post_id): # show the post with the given id, the id is an integer return 'Post %d' % post_id 现有的转换器有:
| int | 接受整数 |
| float | 接受浮点数 |
| path | 和缺省情况相同,但也接受斜杠 |
唯一的 URL / 重定向行为
Flask 的 URL 规则都是基于 Werkzeug 的路由模块的。其背后的理念是保证漂亮的 外观和唯一的 URL 。这个理念来自于 Apache 和更早期的服务器。
假设有如下两条规则:
@app.route('/projects/')def projects(): return 'The project page'@app.route('/about')def about(): return 'The about page' 它们看上去很相近,不同之处在于 URL 定义 中尾部的斜杠。第一个例子中 prjects 的 URL 是中规中举的,尾部有一个斜杠,看起来就如同一个文件夹。访问 一个没有斜杠结尾的 URL 时 Flask 会自动进行重定向,帮你在尾部加上一个斜杠。
但是在第二个例子中, URL 没有尾部斜杠,因此其行为表现与一个文件类似。如果 访问这个 URL 时添加了尾部斜杠就会得到一个 404 错误。
为什么这样做?因为这样可以在省略末尾斜杠时仍能继续相关的 URL 。这种重定向 行为与 Apache 和其他服务器一致。同时, URL 仍保持唯一,帮助搜索引擎不重复 索引同一页面。
URL 构建
如果可以匹配 URL ,那么 Flask 也可以生成 URL 吗?当然可以。 函数就是用于构建指定函数的 URL 的。它把函数名称作为 第一个参数,其余参数对应 URL 中的变量。未知变量将添加到 URL 中作为查询参数。 例如:
>>> from flask import Flask, url_for>>> app = Flask(__name__)>>> @app.route('/')... def index(): pass...>>> @app.route('/login')... def login(): pass...>>> @app.route('/user/ ')... def profile(username): pass...>>> with app.test_request_context():... print url_for('index')... print url_for('login')... print url_for('login', next='/')... print url_for('profile', username='John Doe')...//login/login?next=//user/John%20Doe (例子中还使用下文要讲到的 方法。这个 方法的作用是告诉 Flask 我们正在处理一个请求,而实际上也许我们正处在交互 Python shell 之中,并没有真正的请求。详见下面的 )。
为什么不在把 URL 写死在模板中,反而要动态构建?有三个很好的理由:
- 反向解析通常比硬编码 URL 更直观。同时,更重要的是你可以只在一个地方改变 URL ,而不用到处乱找。
- URL 创建会为你处理特殊字符的转义和 Unicode 数据,不用你操心。
- 如果你的应用是放在 URL 根路径之外的地方(如在
/myapplication中,不在/中), 会为你妥善处理。
HTTP 方法
HTTP ( web 应用使用的协议)) 协议中有访问 URL 的不同方法。缺省情况下,一个路由 只回应 GET 请求,但是可以通过 methods 参数使用不同方法。例如:
@app.route('/login', methods=['GET', 'POST'])def login(): if request.method == 'POST': do_the_login() else: show_the_login_form() 如果当前使用的是 GET 方法,会自动添加 HEAD ,你不必亲自操刀。同时还会确保HEAD 请求按照 (说明 HTTP 协议的文档)的要求来处理,因此你可以 完全忽略这部分 HTTP 规范。与 Flask 0.6 一样, OPTIONS 自动为你处理好。
完全不懂 HTTP 方法?没关系,这里给你速成培训一下:
HTTP 方法(通常也被称为“动作”)告诉服务器一个页面请求要 做 什么。以下是常见 的方法:
- GET
- 浏览器告诉服务器只要 得到 页面上的信息并发送这些信息。这可能是最常见的 方法。 HEAD
- 浏览器告诉服务器想要得到信息,但是只要得到 信息头 就行了,页面内容不要。 一个应用应该像接受到一个 GET 请求一样运行,但是不传递实际的内容。在 Flask 中,你根本不必理会这个,下层的 Werkzeug 库会为你处理好。 POST
- 浏览器告诉服务器想要向 URL 发表 一些新的信息,服务器必须确保数据被保存好 且只保存了一次。 HTML 表单实际上就是使用这个访求向服务器传送数据的。 PUT
- 与 POST 方法类似,不同的是服务器可能触发多次储存过程而把旧的值覆盖掉。你 可能会问这样做有什么用?这样做是有原因的。假设在传输过程中连接丢失的情况 下,一个处于浏览器和服务器之间的系统可以在不中断的情况下安全地接收第二次 请求。在这种情况下,使用 POST 方法就无法做到了,因为它只被触发一次。 DELETE
- 删除给定位置的信息。 OPTIONS
- 为客户端提供一个查询 URL 支持哪些方法的捷径。从 Flask 0.6 开始,自动为你 实现了这个方法。
有趣的是在 HTML4 和 XHTML1 中,表单只能使用 GET 和 POST 方法。但是 JavaScript 和未来的 HTML 标准中可以使用其他的方法。此外, HTTP 近来已经变得相当 流行,浏览器不再只是唯一使用 HTTP 的客户端。比如许多版本控制系统也使用 HTTP 。
转载地址:http://mibgx.baihongyu.com/